A Look at the Technical Side of Our Blog
Our blog is now part of an AI-enabled content system that turns technical expertise into search visibility, market authority, and qualified B2B demand on top of a fast technical foundation.
Our blog is now part of an AI-enabled content system that turns technical expertise into search visibility, market authority, and qualified B2B demand on top of a fast technical foundation.
When this article was first written in 2013, our blog system was much closer to a typical side project: ASP.NET MVC, Markdown, separate summary files, and a lot of logic shaped by the needs of that time.
Today it has become a much more effective system. Our blog is no longer just a place to publish articles. It is part of a digital engine that helps us translate expertise into visibility, authority, and qualified pipeline. We still keep the setup intentionally lean and file-based, so we continue to avoid a traditional CMS or a database for blog content. At the same time, the system is now clearly designed around SEO, multilingual publishing, performance, conversion, and AI-supported workflows.
Do you want content, SEO, and AI to produce measurable business impact?
We help B2B companies build high-performance websites, digital products, and modern content operations where visibility, user experience, and pipeline generation reinforce each other.
Talk to our team
For us, the blog is now a central building block in digital marketing. Expert content should not just be published. It should be discovered, trusted, shared, and turned into meaningful conversations with prospective clients.
That is why the technical foundation is built around three goals:
The last point matters a lot to us. AI is not an isolated experiment in our work. It is part of everyday operations: topic structuring, draft refinement, SEO improvement, translations, quality assurance, and preparing content for additional channels. Our blog system is built so these processes can plug in naturally without making the publishing flow unnecessarily complex.
Today, AI touches almost every relevant step in our content lifecycle. It does not just help with writing. More importantly, it helps us structure, prioritize, refine, and reuse knowledge.
This includes:
The result is not an artificially inflated content machine. It is a more efficient go-to-market content process. Expertise from projects, consulting, and product development can be turned into understandable, search-friendly, and reusable content much faster. That is exactly what we want this system to support.
The core idea has stayed the same: one blog post is one file in the repository. What changed is the structure. Instead of separate summary files, metadata and the actual article content now live in the same Markdown file.
Each article starts with YAML front matter:
---
Title: "A Look at the Technical Side of Our Blog"
Url: "a-look-at-the-technical-side-of-our-blog"
PostDate: 2013-07-29
LastModified: 2026-04-08
AuthorId: 1
ShortDescription: "..."
Tags: "Web, ASP.NET Core"
MetaDescription: "..."
IsIndexable: true
---
The actual Markdown content follows right after that. This format gives us several advantages:
LastModified, MetaDescription, or Faq can be added without database migrationsThis is especially useful for SEO- and AI-supported editorial workflows. When structure and content are cleanly separated but maintained in the same file, briefings, quality checks, optimization steps, and translations become much easier to keep consistent.
The current website runs on ASP.NET Core MVC. The blog is not an external module. It is part of the main website, which means routing, views, localization, conversion paths, and SEO all work together directly.
The system is mainly organized around three building blocks:
BlogController for routing, feeds, and the sitemapBlogFileSystem for loading and preparing articlesThe routes are intentionally straightforward:
/en/blog/ for the English overview/en/blog/{postTitle}/ for individual English articles/blog/ and /blog/{postTitle}/ for the German versions/blog/feed/rss/ for the RSS feed/blog/sitemap.xml for the blog sitemapThat keeps the blog tightly integrated into the overall website architecture. Content pages, service pages, contact touchpoints, and search logic all rely on the same technical foundation. The result is a system where thought leadership, discoverability, and commercial pathways support each other instead of competing for attention.
One thing that matters much more today than it did in 2013 is multilingual publishing. Our content is stored in separate directories by language:
BlogPostsDirectory/deBlogPostsDirectory/enThe current request culture determines which files are loaded. The controller builds the path dynamically based on the language, so the logic stays the same while content remains cleanly separated.
For translated articles, we use not only the primary Url but also an AlternateUrl. That is especially useful for redirects and hreflang relationships. If the slug differs between German and English, the system can still connect both articles correctly.
This is not only relevant for classical internationalization. If you want content to perform internationally today, you need clear language and URL signals for both search engines and AI-driven answer systems.
Not every piece of information belongs inside every Markdown file. That is why we store authors separately in an authors.json file for each language directory.
This includes, for example:
Inside the article, an AuthorId is enough. When a post is loaded, that ID is resolved and enriched with the matching author data. This avoids repeating the same information in every article.
From an SEO and trust perspective, this matters. Clear authorship, technical context, and consistent profiles make expertise more visible and help reinforce credibility.
The system first reads only the metadata from each Markdown file. The YAML front matter is parsed into a BlogPost model. The actual body content is loaded only when a specific article is opened in detail.
That avoids unnecessary work on overview pages. Listing pages need a title, date, teaser, tags, image, and author, but not the full article body.
Only on the detail page is the body loaded and then rendered to HTML with Markdig. We use its advanced Markdown features, which gives us room for richer formatting such as tables, embedded HTML, and more complex article layouts.
AI helps here as well. Before publication, content can be checked more easily for structure, readability, search intent, internal consistency, and meaningful headings without changing the technical publishing model itself. It also becomes easier to derive versions of the same topic for the blog, consulting, social content, and sales communication.
Because our content is file-based, it would make little sense to open and parse every Markdown file for every single request. That is why the blog now uses IMemoryCache.
Among other things, we cache:
The blog list is kept in memory for a few minutes, while author data stays cached much longer. For our use case, that is a pragmatic balance: content does not change every second, but page requests benefit immediately from caching.
This keeps the file-based setup simple without paying the full file-system cost on every request. It also supports fast pages, solid Core Web Vitals, and therefore a better foundation for organic visibility, lower friction, and stronger conversion performance.
For reach, user experience, and conversion, performance is not a side topic. A fast website improves not only how visitors perceive it, but also the technical basis for crawling, ranking, and mobile usage.
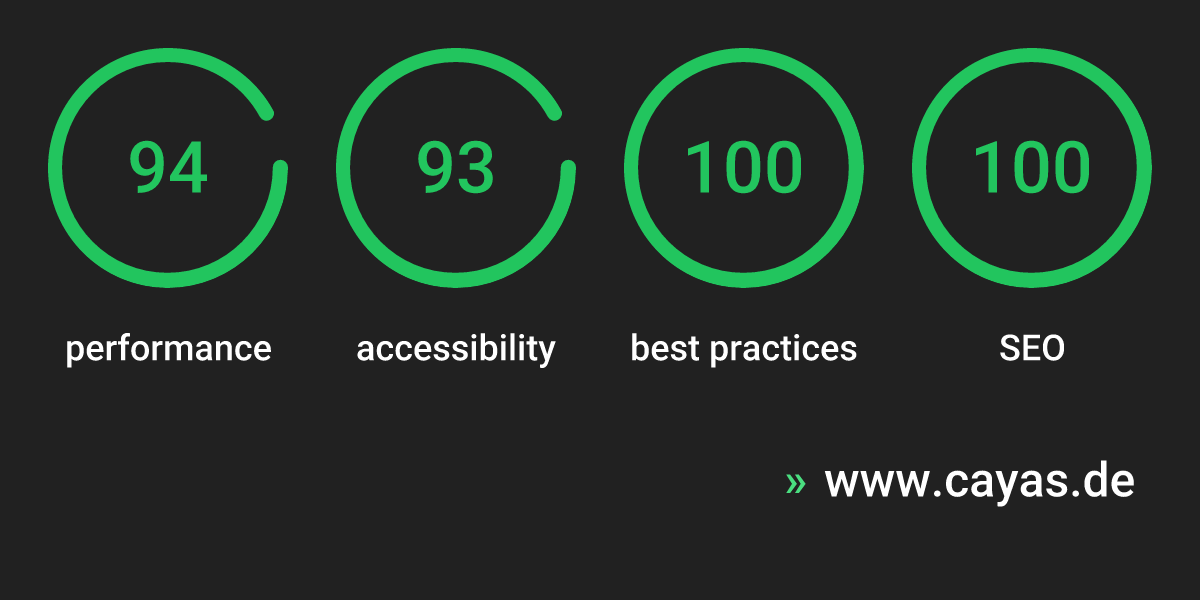
The current public evaluation shows 94 points for performance, 93 for accessibility, and 100 each for best practices and SEO on mobile. For us, that is not vanity. Strong performance directly supports better user experience, stronger organic visibility, and more reliable digital touchpoints.
What used to be an optional extension is now part of the article structure. Tags live directly in the front matter and are reused in several ways:
Related posts are not built with a complex recommendation engine. They are derived from shared tags. For our size and structure, that is simple, transparent, and sufficient.
From a marketing and SEO perspective, this is valuable because it strengthens topical internal linking. Readers can move to the next relevant piece of content more easily, and search engines understand our thematic focus more clearly. At the same time, readers can be guided from educational content into matching offers such as Expert as a Service or our software development services. That makes the blog useful not only for reach, but also for demand capture.
Back in 2013, meta keywords were still part of the conversation. Today, other signals matter much more. That is why our blog system now includes a broader set of SEO and social features driven directly from article data.
These include:
MetaDescription for search snippetscanonical and hreflang links for clean language mappingIsIndexable to control noindex where neededLastModified so updates are easier for search engines to interpretOn top of that, we generate structured data in JSON-LD. Depending on the article, this includes types such as:
BlogPostingBreadcrumbListFAQPageThe FAQ output is especially useful because the relevant questions and answers can be maintained directly in front matter. Content and search markup therefore stay in the same source of truth.
This is one of the most important parts of modern content work for us. Content should not only be readable for people, but also easy to interpret for search engines, answer engines, and AI-based research systems. Structured data, clean metadata, and consistent URL signals are no longer optional.
AI also helps on the editorial side. We use it to structure content more clearly, map search intent better, enrich FAQs where it makes sense, sharpen snippets, and improve existing articles efficiently. That means content is not only created faster, but also aligned more consistently with discoverability, clarity, and conversion.
Our feed and sitemap are no longer based on a separate export step. Instead, they rely on the same article source as the normal blog pages.
The RSS feed is generated server-side as XML. It includes title, description, URL, date, and tags from English blog posts directly from the same source. Additional tag-based filtering is also possible.
The sitemap works in a similar way, but goes further:
lastmod from the article modelhreflang connections between language versionsThis means we do not maintain content, feed, and sitemap three times. Everything is derived from the same Markdown files. That reduces maintenance effort, lowers the risk of inconsistencies, and helps new or updated content enter our broader digital process faster.
A blog only creates real business value for us if content does not live in isolation. That is why we do not think of articles as endpoints. We think of them as entry points into further content, services, and sales conversations.
Expertise is published, made visible through SEO and structured information, and then connected to the rest of the website architecture. That creates clean transitions into relevant services, references, and contact touchpoints without stripping content of its technical depth.
This is also where AI creates additional value in our day-to-day work. Content can be evaluated faster, adapted to specific audiences, transformed into new formats, and fed into further communication or sales processes. In that sense, the blog works not only outwardly, but also as part of our wider digital operating model.
At a time when almost every problem can be solved with a full CMS, it is also worth noting what our blog system deliberately avoids:
That is not a limitation. It is a decision. Our blog is primarily a publishing system for a team that likes working in Git, prefers Markdown, develops content in a data-driven way, and wants full control over content, URLs, markup, and process design.
Do you want one system for website performance, SEO structure, and AI workflows?
Whether you are planning a technical relaunch, a stronger content engine, or the integration of AI into digital operations, we can support you from strategy through implementation.
Explore our software development services
The core idea from back then still holds: content as files, little ballast, and no unnecessary dependencies. But the implementation is much more mature today.
What started as a small ASP.NET MVC experiment has become a structured content system on ASP.NET Core MVC that combines Markdown, YAML front matter, caching, multilingual publishing, structured data, RSS, sitemap generation, and conversion paths in a clean way.
For us, that mix works well: technically lean, flexible in content, strong in SEO, and open to AI-supported processes across the entire value chain. That is why our blog is now far more than a collection of posts. It is a visible part of how we operate digitally and a practical system for turning expertise into reach, trust, and qualified B2B demand.
The Cayas blog runs on ASP.NET Core MVC and uses Markdown files with YAML front matter as its content source. Metadata, structured data, RSS, sitemap generation, multilingual routing, and performance optimizations all work together in one lean file-based system.
Cayas uses Markdown because it keeps content lightweight, version-controlled, and fully manageable in Git. That creates faster review cycles, cleaner content operations, and a strong foundation for technical, SEO-focused, and multilingual publishing.
Cayas uses AI for topic clustering, outlining, FAQ creation, snippet optimization, translations, and improving existing articles. This helps turn technical expertise into structured, search-friendly, and reusable content much faster.
Performance and SEO are core parts of the blog system. Fast load times, structured data, clean metadata, internal linking, and clear language signals improve discoverability, user experience, and the path from content to relevant services.

As a mobile enthusiast and managing director of Cayas Software GmbH, it is very important to me to support my team and our customers in discovering new potential and growing together. Here I mainly write about the development of Android and iOS apps with Xamarin and .NET MAUI.