Ein Blick auf die technische Seite unseres Blogs
Unser Blog ist heute Teil eines KI-gestützten Content-Systems, das Fachwissen sichtbar macht, Suchmaschinen überzeugt und qualifizierte Anfragen mit einer performanten technischen Basis unterstützt.
Unser Blog ist heute Teil eines KI-gestützten Content-Systems, das Fachwissen sichtbar macht, Suchmaschinen überzeugt und qualifizierte Anfragen mit einer performanten technischen Basis unterstützt.
Als dieser Artikel 2013 entstanden ist, war unser Blog-System noch deutlich näher an einem klassischen Bastelprojekt: ASP.NET MVC, Markdown, eigene Summary-Dateien und eine Menge Logik, die sich aus damaligen Anforderungen entwickelt hat.
Heute ist daraus ein deutlich wirkungsvolleres System geworden. Unser Blog ist nicht einfach nur ein Ort für Artikel, sondern Teil eines digitalen Prozesses, mit dem wir Know-how sichtbar machen, Reichweite aufbauen und qualifizierte Anfragen unterstützen. Wir arbeiten weiterhin bewusst schlank und dateibasiert, verzichten also nach wie vor auf ein klassisches CMS oder eine Datenbank für die Blog-Inhalte. Gleichzeitig ist das System heute klar auf SEO, Mehrsprachigkeit, Performance, Conversion und KI-gestützte Arbeitsabläufe ausgelegt.
Sie möchten Content, SEO und KI wirksam zusammendenken?
Wir unterstützen Unternehmen dabei, performante Websites, digitale Produkte und moderne Content-Prozesse so aufzubauen, dass Sichtbarkeit, Nutzererlebnis und Leadgenerierung zusammenspielen.
Lassen Sie uns darüber sprechen
Für uns ist der Blog heute ein zentraler Baustein im digitalen Marketing. Fachartikel sollen nicht nur veröffentlicht, sondern auch gefunden, verstanden, geteilt und in Gespräche mit potenziellen Kunden überführt werden.
Deshalb ist die technische Grundlage auf drei Ziele ausgerichtet:
Gerade die letzte Anforderung ist für uns wichtig. KI ist bei uns kein isoliertes Experiment, sondern Teil der täglichen Arbeit: bei der Themenstrukturierung, bei der Überarbeitung von Entwürfen, bei der SEO-Schärfung, bei Übersetzungen, bei der Qualitätssicherung und bei der Aufbereitung von Inhalten für unterschiedliche Kanäle. Unser Blog-System ist so aufgebaut, dass diese Prozesse einfach andocken können, ohne dass der eigentliche Publikationsweg unnötig kompliziert wird.
Heute begleitet KI bei uns praktisch jeden relevanten Schritt im Content-Lebenszyklus. Sie hilft uns nicht nur beim Schreiben, sondern vor allem beim Strukturieren, Priorisieren, Weiterentwickeln und Wiederverwerten von Wissen.
Dazu gehören unter anderem:
Dadurch entsteht kein künstlich aufgeblähter Content-Fluss, sondern ein deutlich effizienterer Prozess. Fachwissen aus Projekten, Beratung und Produktentwicklung lässt sich schneller in suchmaschinenfähige, verständliche und anschlussfähige Inhalte überführen. Genau diesen Effekt wollen wir mit unserem System unterstützen.
Das Grundprinzip ist gleich geblieben: Ein Blogpost ist eine Datei im Repository. Der Unterschied liegt in der Struktur. Statt separater Summary-Dateien liegen heute sowohl die Metadaten als auch der eigentliche Inhalt in derselben Markdown-Datei.
Jeder Artikel beginnt mit YAML Front Matter:
---
Title: "Ein Blick auf die technische Seite unseres Blogs"
Url: "ein-blick-auf-technische-seite-unseres-blogs"
PostDate: 2013-07-29
LastModified: 2026-04-08
AuthorId: 1
ShortDescription: "..."
Tags: "Web, ASP.NET Core"
MetaDescription: "..."
IsIndexable: true
---
Danach folgt direkt der eigentliche Markdown-Inhalt des Artikels. Dieses Format hat für uns mehrere Vorteile:
LastModified, MetaDescription oder Faq können ohne Datenbank-Migration eingeführt werden.Gerade für SEO- und KI-gestützte Redaktionsprozesse ist das ideal. Wenn Struktur und Inhalt klar getrennt, aber in derselben Datei gepflegt werden, lassen sich Briefings, Qualitätsprüfungen, Optimierungsschritte und Übersetzungen deutlich konsistenter umsetzen.
Die aktuelle Website läuft auf ASP.NET Core MVC. Das Blog-System ist dabei kein externes Modul, sondern Teil der bestehenden Website. Routing, Views, Lokalisierung, Conversion-Pfade und SEO greifen deshalb direkt ineinander.
Die eigentliche Verarbeitung passiert in drei Bausteinen:
BlogController für Routing, Feed und SitemapBlogFileSystem für das Einlesen und Aufbereiten der ArtikelDie Blog-Routen sind bewusst klar gehalten:
/blog/ für die deutsche Übersicht/blog/{postTitle}/ für einen einzelnen deutschen Artikel/en/blog/ und /en/blog/{postTitle}/ für die englischen Varianten/blog/feed/rss/ für den RSS-Feed/blog/sitemap.xml für die Blog-SitemapDamit bleibt das Blog kein Sonderfall, sondern Teil der gesamten Informationsarchitektur der Website. Fachinhalte, Leistungsseiten, Kontaktpunkte und Suchmaschinenlogik arbeiten auf derselben technischen Basis zusammen.
Ein Punkt, der heute wesentlich wichtiger ist als 2013, ist die Mehrsprachigkeit. Unsere Inhalte liegen getrennt nach Sprache in zwei Verzeichnissen:
BlogPostsDirectory/deBlogPostsDirectory/enWelche Dateien geladen werden, entscheidet die aktuelle Kultur der Anfrage. Der Controller baut den Pfad also dynamisch anhand der Sprache auf. Dadurch bleibt die Logik für beide Sprachversionen identisch, während die Inhalte sauber getrennt bleiben.
Für übersetzte Artikel nutzen wir neben der eigentlichen Url auch eine AlternateUrl. Das ist vor allem für Weiterleitungen und hreflang-Verknüpfungen hilfreich. Wenn sich Slugs zwischen deutscher und englischer Version unterscheiden, kann das System beide Seiten trotzdem korrekt miteinander verknüpfen.
Das ist nicht nur für klassische Internationalisierung relevant, sondern auch für moderne Suchoberflächen. Wer Inhalte heute international sichtbar machen will, muss sowohl Suchmaschinen als auch KI-gestützten Antwortsystemen eindeutige Sprach- und URL-Signale liefern.
Nicht jede Information gehört in jede einzelne Markdown-Datei. Autoren verwalten wir deshalb separat in einer authors.json pro Sprachverzeichnis.
Darin stehen unter anderem:
Im Artikel selbst reicht dann eine AuthorId. Beim Laden eines Blogposts wird diese ID aufgelöst und um die passenden Autorendaten angereichert. Das vermeidet doppelte Pflege in jedem einzelnen Artikel.
Aus SEO- und Vertrauenssicht ist das ein wichtiger Punkt. Klare Autorenzuordnung, fachliche Einordnung und konsistente Profile stärken die Glaubwürdigkeit unserer Inhalte und helfen dabei, Expertise sichtbar zu machen.
Das System liest zunächst nur die Metadaten der Markdown-Dateien ein. Dafür wird das YAML Front Matter geparst und in ein BlogPost-Modell überführt. Der eigentliche Body wird erst dann nachgeladen, wenn ein Artikel wirklich im Detail aufgerufen wird.
Das reduziert unnötige Arbeit auf Übersichtsseiten. Listenansichten benötigen schließlich nur Titel, Datum, Teaser, Tags, Bild und Autor, aber nicht den kompletten Artikeltext.
Erst auf der Detailseite wird der Body geladen und anschließend mit Markdig zu HTML gerendert. Wir nutzen dabei die erweiterten Markdown-Funktionen, sodass auch komplexere Inhalte wie Tabellen, HTML-Einbettungen oder erweiterte Formatierungen möglich sind.
Auch hier hilft uns KI im Prozess: Inhalte lassen sich vor der Veröffentlichung leichter auf Struktur, Lesbarkeit, Suchintention, interne Konsistenz und sinnvolle Zwischenüberschriften prüfen, ohne dass wir das technische Publikationsmodell verändern müssen. Gleichzeitig wird es einfacher, aus einem Fachthema unterschiedliche Varianten für Blog, Beratung, Social Content und Vertriebskommunikation abzuleiten.
Da unsere Inhalte dateibasiert sind, wäre es wenig sinnvoll, bei jedem Request alle Markdown-Dateien neu zu öffnen und neu zu parsen. Deshalb arbeitet das Blog-System heute mit IMemoryCache.
Gecacht werden unter anderem:
Die Blog-Liste wird für einige Minuten im Speicher gehalten, Autoren sogar deutlich länger. Das reicht für unseren Einsatzzweck gut aus: Inhalte ändern sich selten sekundenaktuell, Seitenaufrufe profitieren aber sofort von der Zwischenspeicherung.
Der Effekt ist angenehm pragmatisch: Wir behalten das einfache dateibasierte Setup, ohne bei jeder Anfrage die volle Dateisystem-Last zu zahlen. Das sorgt für schnelle Seiten, saubere Core Web Vitals und damit auch für eine bessere Grundlage in der organischen Sichtbarkeit.
Für Reichweite, Nutzererlebnis und Conversion ist Performance kein Nebenthema. Eine schnelle Website verbessert nicht nur die Wahrnehmung bei Besuchern, sondern auch die technische Grundlage für Crawling, Ranking und die Nutzung in mobilen Kontexten.
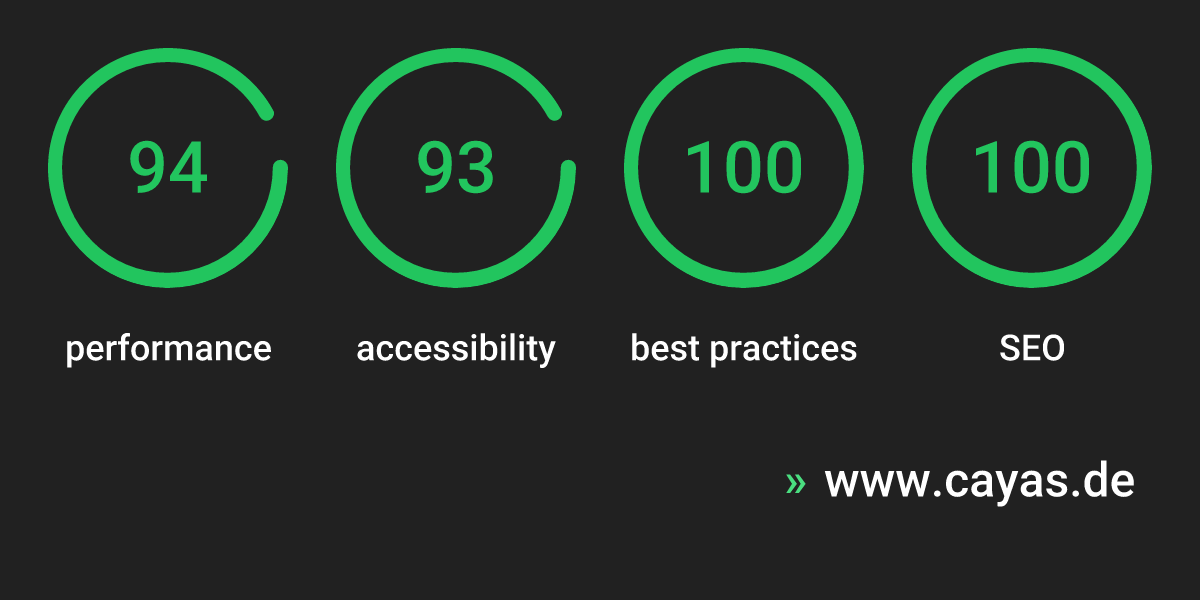
Die aktuelle öffentliche Auswertung zeigt 94 Punkte für Performance, 93 für Accessibility sowie jeweils 100 für Best Practices und SEO auf Mobilgeräten. Für uns ist das kein Selbstzweck. Hohe Performance ist ein direkter Hebel für bessere Nutzererfahrung, stärkere organische Sichtbarkeit und belastbare digitale Touchpoints.
Was früher noch als Erweiterung diskutiert wurde, ist heute fester Bestandteil der Artikelstruktur. Tags werden direkt im Front Matter hinterlegt und mehrfach genutzt:
Die verwandten Artikel entstehen dabei nicht über ein komplexes Recommendation-System, sondern über gemeinsame Tags. Das ist einfach, nachvollziehbar und für unsere Artikelgröße völlig ausreichend.
Für Marketing und SEO ist das wertvoll, weil thematisch passende interne Verlinkungen automatisch gestützt werden. Leser finden schneller den nächsten relevanten Inhalt und Suchmaschinen erkennen unsere thematischen Schwerpunkte klarer. Gleichzeitig lassen sich Nutzer aus Wissensinhalten gezielt in passende Angebote wie Expert as a Service oder unsere Software-Entwicklung weiterführen.
2013 waren Meta-Keywords noch ein Thema. Heute spielen andere Signale eine deutlich größere Rolle. Deshalb enthält unser Blog-System inzwischen eine Reihe von SEO- und Social-Funktionen, die direkt aus den Artikeldaten gespeist werden.
Dazu gehören:
MetaDescription für Suchmaschinen-Snippetscanonical- und hreflang-Links für sprachsaubere ZuordnungIsIndexable, um einzelne Seiten gezielt auf noindex zu setzenLastModified, damit Suchmaschinen Aktualisierungen besser einordnen könnenZusätzlich erzeugen wir strukturierte Daten im JSON-LD-Format. Je nach Artikel werden dabei unter anderem diese Typen ausgegeben:
BlogPostingBreadcrumbListFAQPageGerade die FAQ-Ausgabe ist praktisch, weil sich die entsprechenden Fragen und Antworten direkt im Front Matter pflegen lassen. Inhalt und Suchmaschinen-Markup bleiben damit in derselben Quelle.
Das ist für uns einer der wichtigsten Punkte in der heutigen Content-Arbeit: Inhalte sollen nicht nur für Menschen gut lesbar sein, sondern auch für Suchmaschinen, Antwortmaschinen und KI-basierte Recherche-Systeme möglichst klar interpretierbar. Strukturierte Daten, saubere Metadaten und konsistente URL-Signale sind dafür keine Kür mehr, sondern Pflicht.
KI hilft uns dabei zusätzlich auf redaktioneller Ebene. Wir nutzen sie, um Inhalte zielgerichteter zu strukturieren, Suchintentionen besser abzubilden, FAQs sinnvoll zu ergänzen, Snippets zu schärfen und bestehende Beiträge effizient weiterzuentwickeln. So werden Inhalte nicht nur schneller erstellt, sondern auch konsistenter auf Auffindbarkeit, Verständlichkeit und Conversion ausgerichtet.
Auch Feed und Sitemap basieren heute nicht auf einem separaten Export-Schritt. Stattdessen greifen sie direkt auf dieselbe Artikelquelle zu wie die normalen Blogseiten.
Der RSS-Feed wird serverseitig als XML erzeugt. Dabei landen Titel, Beschreibung, URL, Datum und Tags der englischen Blogposts direkt im Feed. Eine zusätzliche Tag-Filterung ist ebenfalls möglich.
Die Sitemap arbeitet ähnlich, geht aber noch weiter:
lastmod aus dem Artikelmodellhreflang-Verknüpfungen zwischen SprachversionenDamit pflegen wir Inhalte, Feed und Sitemap nicht dreifach, sondern leiten alles aus denselben Markdown-Dateien ab. Das spart Pflegeaufwand, reduziert Fehlerquellen und sorgt dafür, dass neue oder überarbeitete Inhalte schneller in unseren digitalen Prozess aufgenommen werden.
Ein Blog bringt für uns nur dann echten geschäftlichen Wert, wenn Inhalte nicht isoliert stehen. Deshalb denken wir Artikel nicht als Endpunkt, sondern als Einstieg in weiterführende Inhalte, Leistungen und Gespräche.
Fachwissen wird veröffentlicht, über SEO und strukturierte Informationen sichtbar gemacht und anschließend in die übrige Website-Architektur eingebettet. So entstehen klare Übergänge zu passenden Leistungen, Referenzen und Kontaktpunkten, ohne dass der Content seinen fachlichen Charakter verliert.
Gerade an diesen Übergängen entfaltet KI in unserem Alltag zusätzlichen Nutzen. Inhalte können schneller bewertet, auf Zielgruppen angepasst, in neue Formate überführt und in weitere Vertriebs- oder Kommunikationsprozesse eingespeist werden. So wirkt unser Blog nicht nur nach außen, sondern auch innerhalb unserer gesamten digitalen Arbeitsweise.
Gerade weil heute fast jedes Problem mit einem vollwertigen CMS gelöst werden kann, ist auch interessant, was unser Blog-System bewusst nicht mitbringt:
Das ist keine Lücke, sondern eine Entscheidung. Unser Blog ist in erster Linie ein Publishing-System für ein Team, das gern in Git arbeitet, Markdown mag, Inhalte datengetrieben weiterentwickelt und volle Kontrolle über Inhalte, URLs, Markup und Prozesse behalten will.
Sie möchten Website-Performance, SEO-Struktur und KI-Workflows in einem System zusammenbringen?
Ob technischer Relaunch, Content-Prozess oder die Integration von KI in digitale Abläufe: Wir unterstützen Sie von der Konzeption bis zur Umsetzung.
Mehr über unsere Software-Entwicklung
Die Grundidee von damals hat sich gehalten: Inhalte als Dateien, wenig Ballast, keine unnötigen Abhängigkeiten. Die konkrete Umsetzung ist heute aber deutlich moderner.
Aus einem kleinen ASP.NET-MVC-Experiment ist ein klar strukturiertes Content-System auf ASP.NET Core MVC geworden, das Markdown, YAML Front Matter, Caching, Mehrsprachigkeit, strukturierte Daten, RSS, Sitemap und Conversion-Pfade sauber miteinander verbindet.
Für uns funktioniert genau diese Mischung gut: technisch schlank, inhaltlich flexibel, SEO-stark und offen für KI-gestützte Prozesse entlang der gesamten Wertschöpfungskette. Genau deshalb ist unser Blog heute weit mehr als eine Sammlung von Artikeln: Er ist ein sichtbarer Teil unserer digitalen Arbeitsweise und ein Baustein dafür, aus Expertise Reichweite, Vertrauen und neue Nachfrage zu entwickeln.
Der Cayas-Blog basiert auf ASP.NET Core MVC und nutzt Markdown-Dateien mit YAML Front Matter als Content-Quelle. Metadaten, strukturierte Daten, RSS, Sitemap, Mehrsprachigkeit und Performance-Optimierungen werden in einem schlanken dateibasierten System zusammengeführt.
Cayas setzt auf Markdown, weil Inhalte damit leichtgewichtig, versionierbar und vollständig kontrollierbar bleiben. In Kombination mit Git entstehen schnelle Review-Prozesse, saubere URLs und eine sehr gute Basis für technische, SEO-orientierte und mehrsprachige Content-Arbeit.
Cayas nutzt KI für Themencluster, Gliederungen, FAQ-Entwicklung, Snippet-Optimierung, Übersetzungen und die Weiterentwicklung bestehender Inhalte. Dadurch wird Fachwissen schneller in klar strukturierte, suchmaschinenfähige und kanalübergreifend nutzbare Inhalte überführt.
Performance und SEO sind zentrale Bausteine des Blog-Systems. Schnelle Ladezeiten, strukturierte Daten, klare Metadaten, interne Verlinkungen und saubere Sprachsignale verbessern Sichtbarkeit, Nutzererlebnis und den Übergang in passende Leistungen.

Als Mobile-Enthusiast und Geschäftsführer der Cayas Software GmbH ist es mir ein großes Anliegen, mein Team und unsere Kunden zu unterstützen, neue potenziale zu entdecken und gemeinsam zu wachsen. Hier schreibe ich vor allem zur Entwicklung von Android und iOS-Apps mit Xamarin und .NET MAUI.